In our first blog post, we examine differences between Anonymisation and Pseudonymisation.
It is interesting to note that GDPR’s recommendation is to pseudonymise personal data wherever possible. A fundamental principle of the EU’s General Data Protection Regulation (GDPR), which came into force on 25 May 2018, is the recommendation to pseudonymise personal data wherever possible. Articles 4, 6, 25, 32, 40 and 89, as well as recitals 28, 29, 75, 78, 85 and 156 of the GDPR, explicitly mention pseudonymisation. While this is deemed sufficient, it does not preclude other means of data protection (Recital 28). GDPR does not refer to anonymisation anywhere in those articles and recitals.
What do we mean by Anonymisation and Pseudonymisation
Let’s look at an ideal and perfect scenario: anonymization. According to GDPR, anonymisation is the processing of data so that it cannot be identifiable as being associated with a particular individual. For a truly effective anonymisation, it has to become impossible for readers of the resulting data to carry out the identification of the person originally associated with the data – even with the help of other knowledge about the anonymised data.
This ideal scenario presents a problem for data controllers and data processors because the data is also rendered useless for most analytics. Let’s have a look at the anonymisation options below.

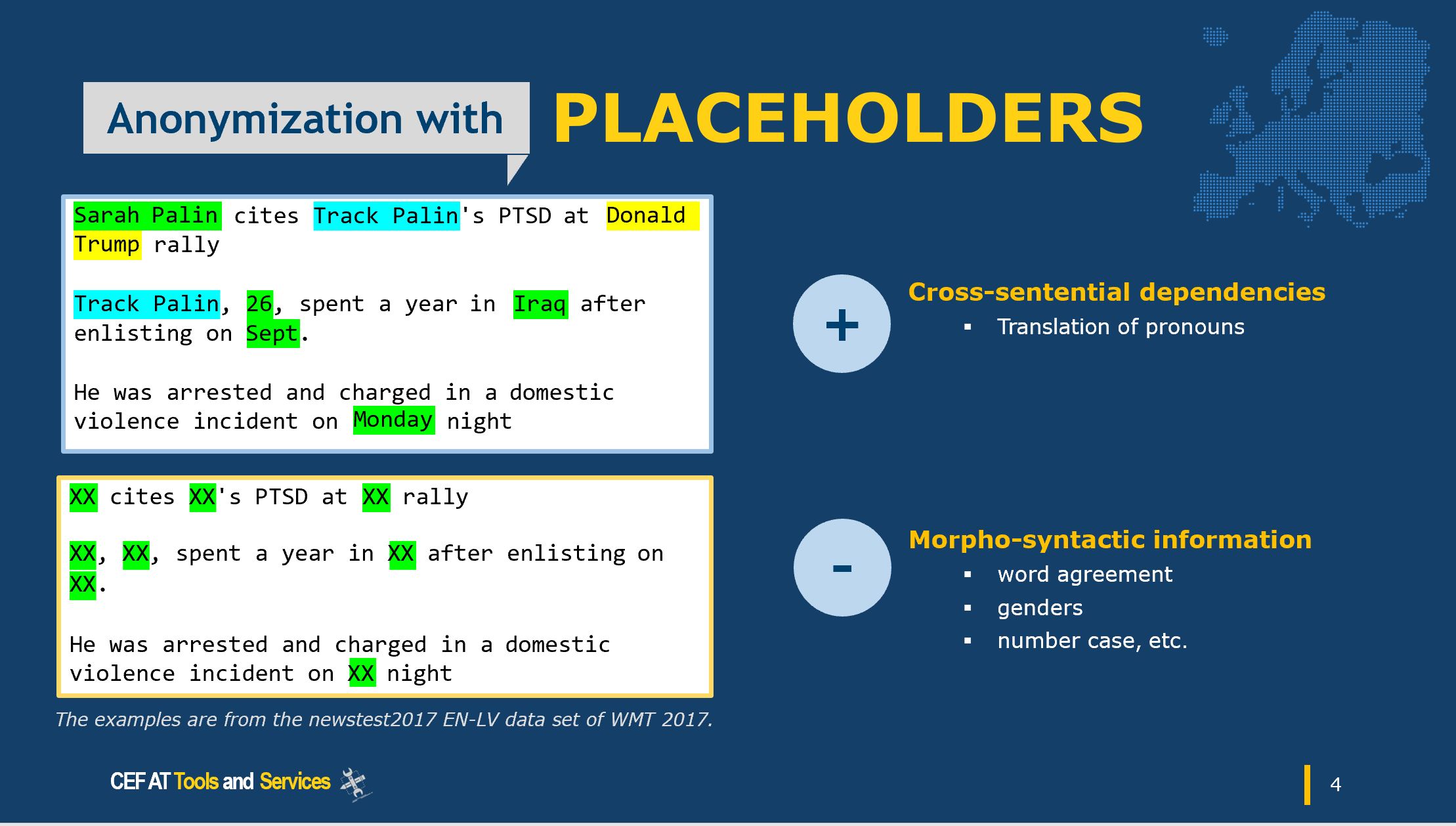

In the next blog post of our GDPR compliance series, we will review all these techniques and how they can become useful for Public Administrations, the focus of our project, as well as common element-level protection techniques. We will also show and map anonymisation and pseudonymisation to those techniques.
Doing without the ability to do valuable analytics could be one explanation for GDPR’s omission of the terms anonymisation. Nevertheless, anonymized data can still be useful for development and testing use cases and MAPA will provide the three options as part of its deliverables.
Let’s consider a potential use at a Public Administration with a table below
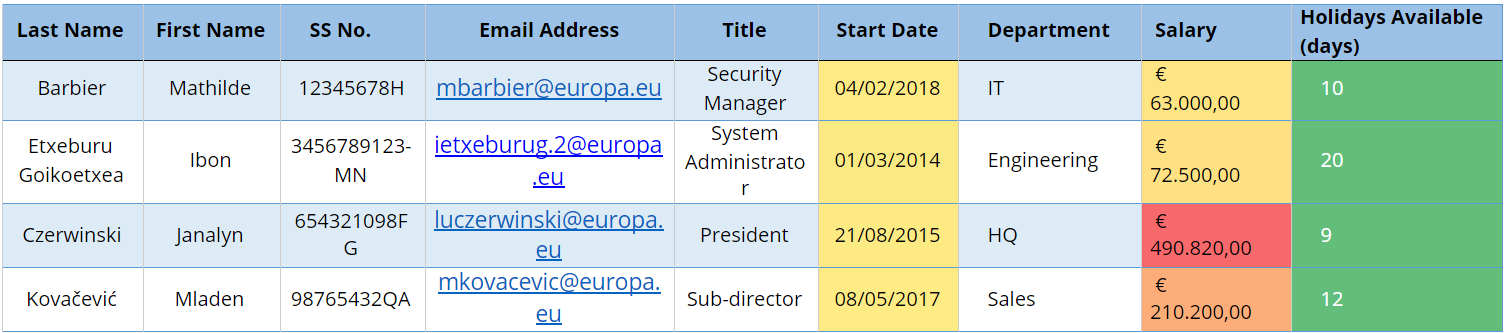 Fig 1 — Table before anonymisation
Fig 1 — Table before anonymisation
after anonymisation, the table could look like the one below (Fig 2).
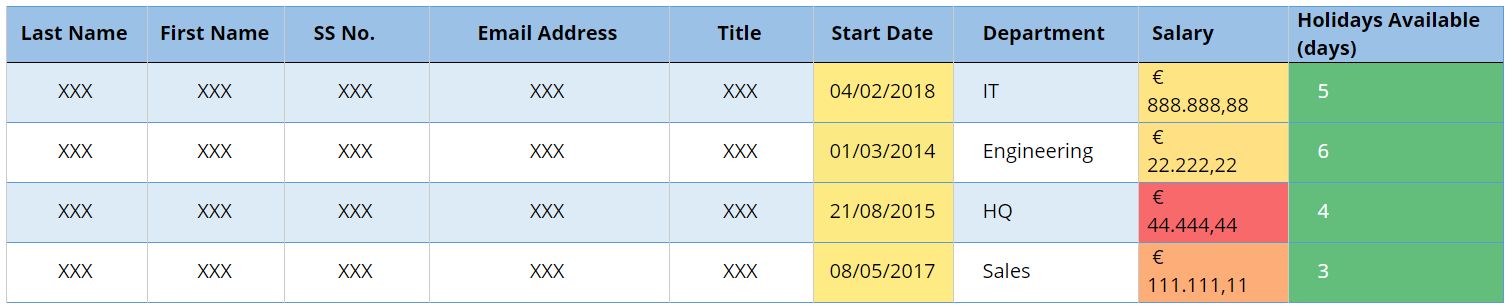 Fig 2 — Table after anonymisation
Fig 2 — Table after anonymisation
Which is provides extreme untraceability and looks very secure but it is of little use we plan to process it in any way since the process is irreversible.
Now let’s consider pseudonymization. Let us assume that in addition to the “Department” column the “Salary” column is also not modified for whatever reason (for example being an item that has not been identified as essential in our anonymization procedures or we are using a software that does not allow to do that). The following table (Fig 3) results from that action rather than the table in Fig 2.
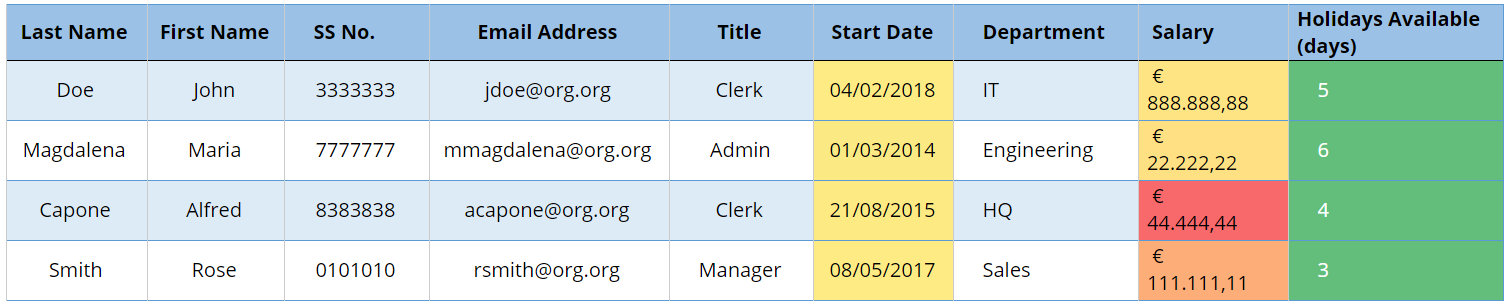 Fig 3 — Table after Pseudonymisation (Case A).
Fig 3 — Table after Pseudonymisation (Case A).
Note that every cell in the spreadsheet has been modified in Fig 3 just as in Fig 2, except “Department”. The assumption is that each department consists of more than one person and, therefore, getting back to the original data is not possible, even if we made use of additional external information. However, if Sales or Engineering were a single-person department, then we could have the person’s record. But as all the other values apart from “Department” are also anonymized, obtaining or finding out that external information would be useless to anyone with access to the record.
But let’s assume our anonymization software does not take salary information to be relevant (in fact, it is not a stated requirement of either GDPR, CCPA / HIPPA / NIST, Japanese APPI or Brazilian LGPD).
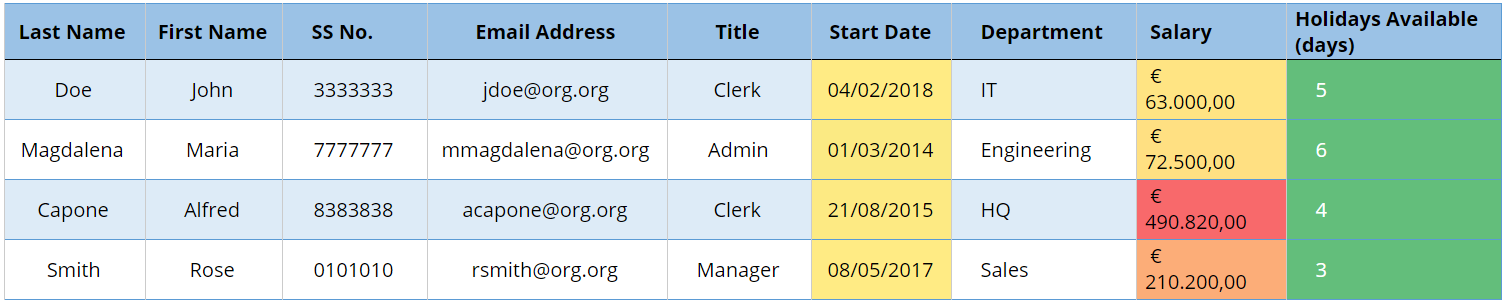 Fig 3 — Table after Pseudonymisation (Case B)
Fig 3 — Table after Pseudonymisation (Case B)
If President Janalyn Czerwinski (row 3) had not been in the data set, this pseudoanonymised Case B would have been equivalent to an anonymized set. However, since the “Salary” record has not been modified, the significant outlier in that column (over €490,000) gives away the identity and salary information of the highest official. To put it simple, the knowledge that the President or the person with the highest responsibility in an organisation is likely to earn well above everyone else basically re-identifies the record even though it has been pseudonymised.
In all the examples above, since the number of fields transformed is substantial in comparison with the total number of fields, the data, while usable for testing, is rendered useless for meaningful analysis. To be able to draw meaningful conclusions, the fields of interest in analysis need to be available without transformation —or at least be in the same range— so that aggregate results are the same.
Organisations, from Public Administrations to corporations, should have an insight into the data they are processing. They should also minimise the use, collection, and retention of PII or Personal Data to what is strictly necessary to accomplish their business purpose, and implement proper procedures and technical and organisational safeguards.
The degree of anonymization and indeed whether a data set is irreversibly anonymized or pseudonymized for further processing and the variety of techniques greatly depend on the nature of the un-transformed data and how much it might reveal. In our example today, that “sufficient additional information” is the logical assumption that the President of an organisation is very likely the highest paid employee in the company. Additional information might be public information or data available in other tables or data stores in the organization.
As we saw in the discussion above, anonymization and pseudonymization are distinct approaches that protect data as a whole, in the aggregate. The effects of anonymization and pseudonymization are achieved by applying transformations at the unit (element) level. We will delve into these element level techniques in the next blog post and map those techniques to anonymization and pseudonymization.