Action completion
The MAPA Action has run through the middle of the first, second and third waves of the pandemic, ending in December 2021 at the beginning of the 6th wave (omicron). Undoubtedly, the first lockdowns that took place in Europe from March 2020 had an effect in the way the project had to be managed (full remote) and of course in the in-person gatherings for national dissemination that had to take place.
Nevertheless, and despite the above, MAPA has not experienced any major deviations in the final results, deliverables and objectives, with the large language community and European institutions being aware of the importance of anonymisation and MAPA becoming a reference point as the first truly multilingual open-source software available for Public Administrations with reference Use Cases. The MAPA docker is a usable, solid piece of software that can be used as set of language independent engines or as a general multilingual piece of software that can be integrated in document processing or other processes for general-purpose anonymisation, with a specialism in the legal and health domains.
MAPA can be deployed easily as all engines are fully dockerised. The integrity for use at Public Administrations has been independently tested by partner LIMSI (CNRS) as a specialist in de-identification software and tried at the engaged Use Cases (Spanish Ministry of Justice, Complaints Watch by DG-Justice). The security features are standard internet https:// compliant and those of a docker system as use in all cases has been internal to each organisation. An AS4 Domibus compliant connection is possible as planned for SaaS implementations. The docker can easily be connected to popular Computer Assisted Tools (CAT) used at Public Administrations to speed up the work of translators or build on them for full anonymisation during document translation processes, for example. Another use is as implemented by Complaints Watch (anonymisation of Excel files) or Spanish MoJ (documents, with document reconstruction taking place externally).
The consortium’s sustainability plan is designed to lead potentially to a source of revenue having European Public Administrations as clients and potentially fork out and further develop the tool to create other distributions and commercial solutions in the future. Furthermore, the Action has engaged several organisations as part of an interest group: members of the language association GALA, users of the European Language Grid. Several language service providers have expressed their interest in getting hold of the open-source version in GitLab (December 2021-January 2022). The set of engines are for free for European Public Administrations and the general public at large to download and implement (through ELG or GitLab). Consultancy and/or maintenance contracts may add to the software maintenance and product viability and sustainability as well as anonymisation engine updates.
All partners are committed to the maintenance of the product as part of its software portfolio offering. The anonymisation engines are and will remain an open-source MT engine system that can also be used as an academic benchmark to further the state-of-the-art. MAPA, as a set of anonymisation engines and a private deployment is possible either in a European cloud or with on-premises deployments when privacy requires no outside connections.
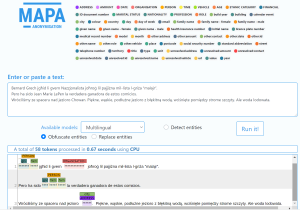


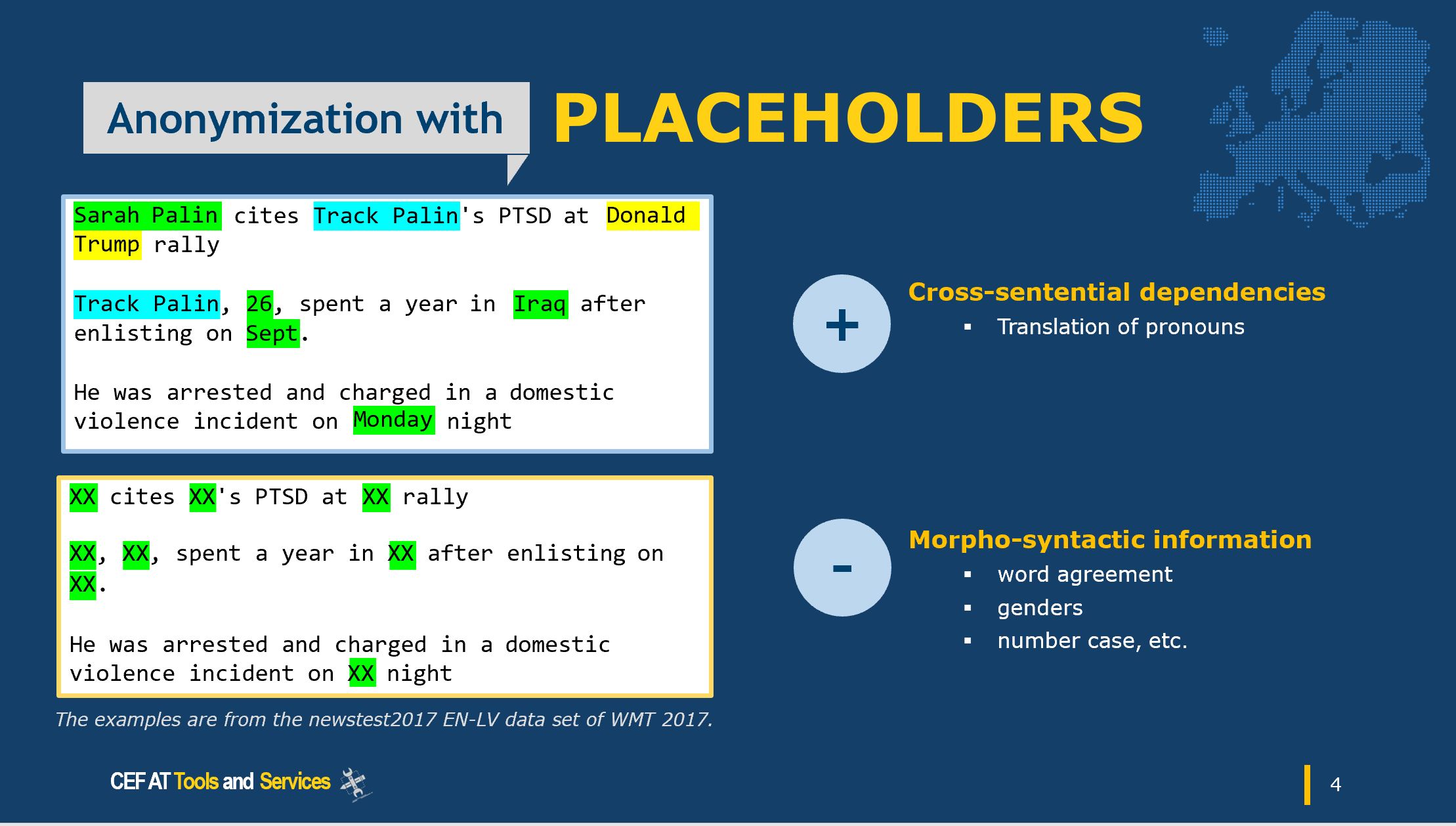

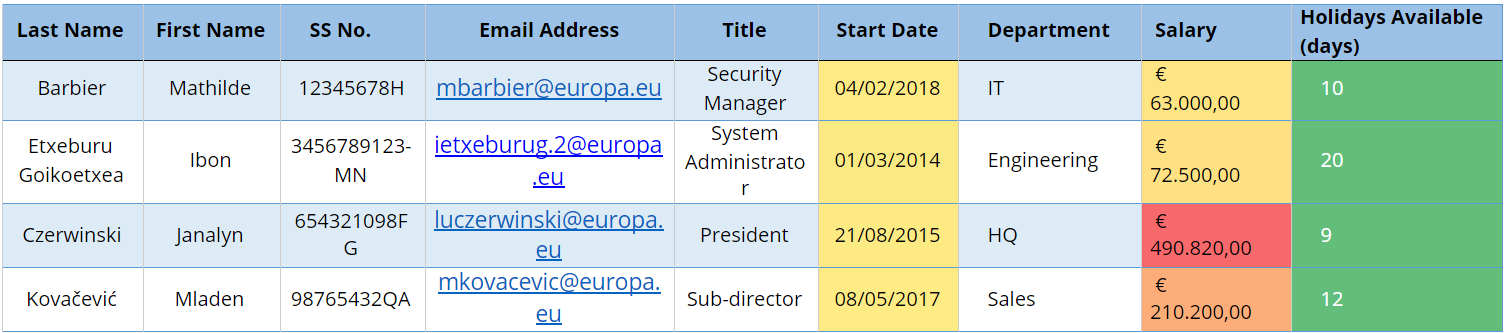 Fig 1 — Table before anonymisation
Fig 1 — Table before anonymisation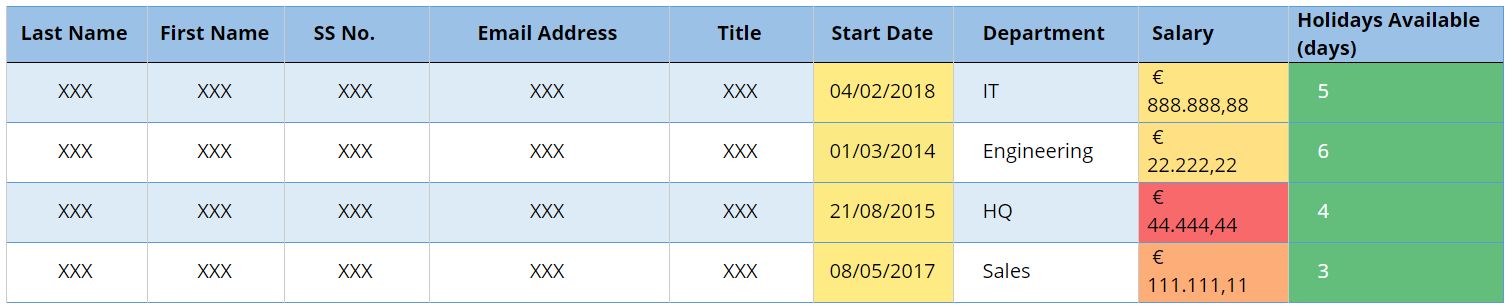 Fig 2 — Table after anonymisation
Fig 2 — Table after anonymisation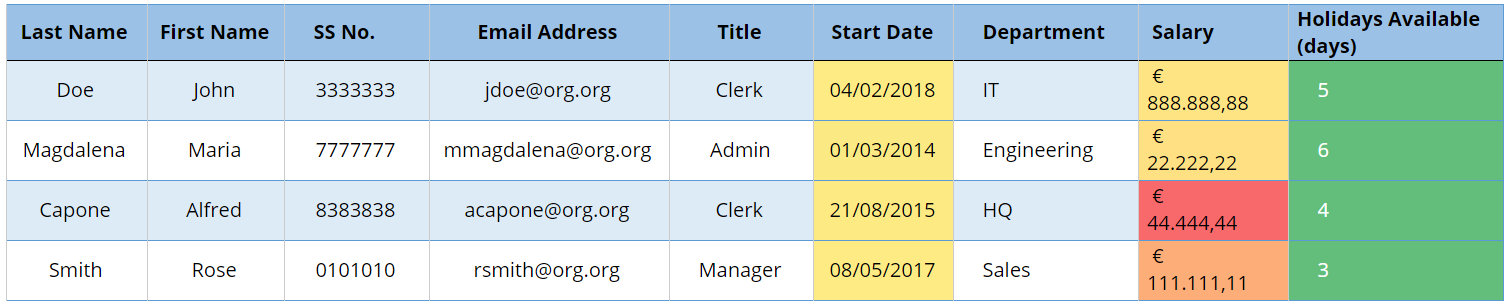 Fig 3 — Table after Pseudonymisation (Case A).
Fig 3 — Table after Pseudonymisation (Case A).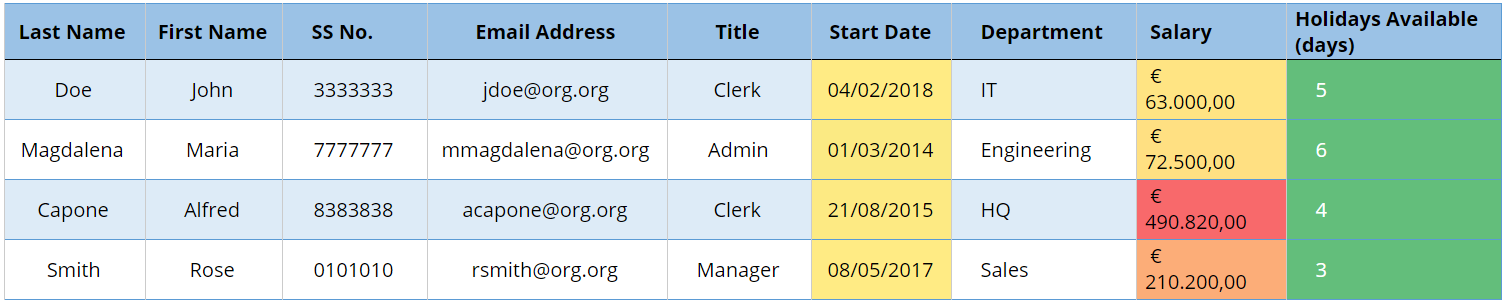 Fig 3 — Table after Pseudonymisation (Case B)
Fig 3 — Table after Pseudonymisation (Case B)