Data Anonymisation is the process of encrypting or removing personal data or personally identifiable data (in order to protect private or sensitive information) from data sets so that the person can no longer be identified directly or indirectly. Identifiers such as contact data, names, addresses, social security numbers etc., are erased or encrypted so the individual cannot be traced back to the stored data. When a person cannot be re-identified the data is no longer considered personal data and GDPR does not apply. Running software such as MAPA’s open source docker will make personal data disappear through Anonymisation or Pseudonymisation techniques, making it possible for Public Administrations to easily deploy truly multilingual anonymisation to their data sets.
However, there is always a possibility that even data is cleared of identifiers, attackers could use de-anonymisation techniques in a sort of back-engineering to link the anonymised personal data to the person. Since data usually may be transferred through multiple sources and some can be available to the public, potential de-anonymisation techniques could cross-reference the sources and reveal personal information.
The General Data Protection Regulation (GDPR) outlines a specific set of rules that protect citizens and user data and create transparency in information sharing. GDPR is the strictest data privacy regulation in the world, but it allows companies to collect anonymised data without consent, use it for any purpose, and store it for an indefinite time as long as companies remove all identifiers from the data.

Data Anonymisation Techniques
- Data Masking, that is, hiding data with altered values such as placeholders, gaps, etc. You can create a mirror version of a database and apply modification techniques such as word or character substitution, character shuffling or encryption. For example, you can replace a value character with a symbol such as “*” or “x”. This type of irreversible anonymisation makes reverse engineering or detection impossible.
- Pseudonymization is a data management and de-identification method that replaces private identifiers with pseudonyms (that is invented or fake identifiers). For example, this table showing current Italian ministers completely identifies the person as the one holding office at a Ministry
Minister
Mit Geschäftsbereich
| Amt oder Ressort | Bild | Name | Partei | |
| Arbeit und Sozialpolitik | Andrea Orlando | PD | ||
| Auswärtiges und internationale Zusammenarbeit | Luigi Di Maio | M5S | ||
| Gesundheit | Roberto Speranza | Art. 1 | ||
| Infrastruktur und Verkehr | Enrico Giovannini | parteilos | ||
| Inneres | Luciana Lamorgese | parteilos | ||
| Justiz | Marta Cartabia | parteilos | ||
| Kultur | Dario Franceschini | PD | ||
| Landwirtschaft, Ernährung und Forstwirtschaft | Stefano Patuanelli | M5S | ||
| Ökologischer Übergang | Roberto Cingolani | parteilos | ||
| Universitäten und Forschung | Maria Cristina Messa | parteilos | ||
| Unterricht | Patrizio Bianchi | parteilos | ||
| Verteidigung | Lorenzo Guerini | PD | ||
| Wirtschaft und Finanzen | Daniele Franco | parteilos | ||
| Wirtschaftliche Entwicklung | Giancarlo Giorgetti | Lega | ||
could be pseudoanonymised with MAPA as
Work
Mit Geschäftsbereich
| Amt oder Ressort | Bild | Name | Partei | |
| Arbeit und Sozialpolitik | Ana Maria Lynch | G6E9 | ||
| Auswärtiges und internationale Zusammenarbeit | Olga Simoneva | B3B0 | ||
| Gesundheit | Ernest van Dyck | C2C | ||
| Infrastruktur und Verkehr | Viljar Mälk | m1A2 | ||
| Inneres | Olof Mann | n1A2 | ||
| Justiz | Roberto Rossi | B1A2 | ||
| Kultur | Alexander Owloski | C6E9 | ||
| Landwirtschaft, Ernährung und Forstwirtschaft | Jordi Lluch | Q23s | ||
| Ökologischer Übergang | Else Frandsen | X7V2 | ||
| Universitäten und Forschung | Alberto Casamonte | D2D3 | ||
| Unterricht | Cristina Longo | Bg06 | ||
| Verteidigung | Jennifer Low | 5TGR | ||
| Wirtschaft und Finanzen | Aristoteles Myriakos | 2D40 | ||
| Wirtschaftliche Entwicklung | Deborah C. Myers | K1FF | ||
Note that not only names but also political affiliation has been substituted in order to mask any trace. Also, there is no relation between the original gender and the pseudonymised. Of course, we could apply world knowledge and find out who the Minister for Universities is, and that is why the “Minister” term has also been pseudonymised. Political affiliation has been masked, too, using synthetic random data (see below). Thus, the table could belong to any job category. Pseudonymization preserves statistical accuracy and data integrity, allowing the modified data to be used for training, development, testing, and analytics while protecting data privacy.
- Data perturbation: modifies the original dataset slightly by applying techniques that round numbers and add random noise. The range of values needs to take into account the proportion to the perturbation (years, membership, work, term in office). A small base may lead to weak anonymization while a large base can reduce the utility of the dataset. For example, you can use a base of 5 or 10 for rounding values like age or house number because it’s proportional to the original value. However, using multipliers like x25 may make the memberships, work history, term in office or people’s age fake.
- Synthetic data is algorithmically manufactured information that has no connection to real events. Synthetic data is used to create artificial datasets for names, addresses, political groups or other identifiers instead of altering the original dataset or using it as is and risking privacy and security. The process involves previously creating statistical models which can be based on general data (people’s names, street names, etc.) and patterns found in the original dataset. Alternatively, methods such as standard deviations, medians, linear regression or other statistical techniques can be used to generate the synthetic data.
- Generalization (not a full GDPR compliant technique) removes some of the data to make it less identifiable. For example, the house number in an address can be removed, but not the road name. The purpose is to eliminate some of the identifiers whilst retaining a measure of data accuracy. Data is thus partly obfuscated into a broad area or set of ranges with appropriate boundaries.
- Data shuffling, also known as swapping or permutation. Here, the dataset attribute values are rearranged so they don’t correspond with the original records.
Disadvantages of Full Data Anonymisation
GDPR stipulates that websites have to obtain explicit consent from their users to collect personal information such as IP addresses, device ID, and cookies, something that all website managers are aware of nowadays. GDPR does not tend to speak about full data anonymisation as that would have to absolutely guarantee that even applying external knowledge the individual or individuals mentioned in a data set could not be identified. Also, data anonymisation is an irreversible process and that is why the technique usually applied is pseudonymisation. Commercially speaking, collecting anonymous data and deleting the identifiers from the database limits the ability to derive value and insights from it. However, it allows Public Administrations to comply with Open Data directives and share citizens’ data safely. The Multilingual Anonymisation for Public Administrations (MAPA) project has been created with the needs of Public Administrations in mind. In commercial environments, anonymised data clearly loses value as it cannot be used for marketing efforts, or to personalize the website’s user experience. The selling of un-anonymised personal data is strictly forbidden.

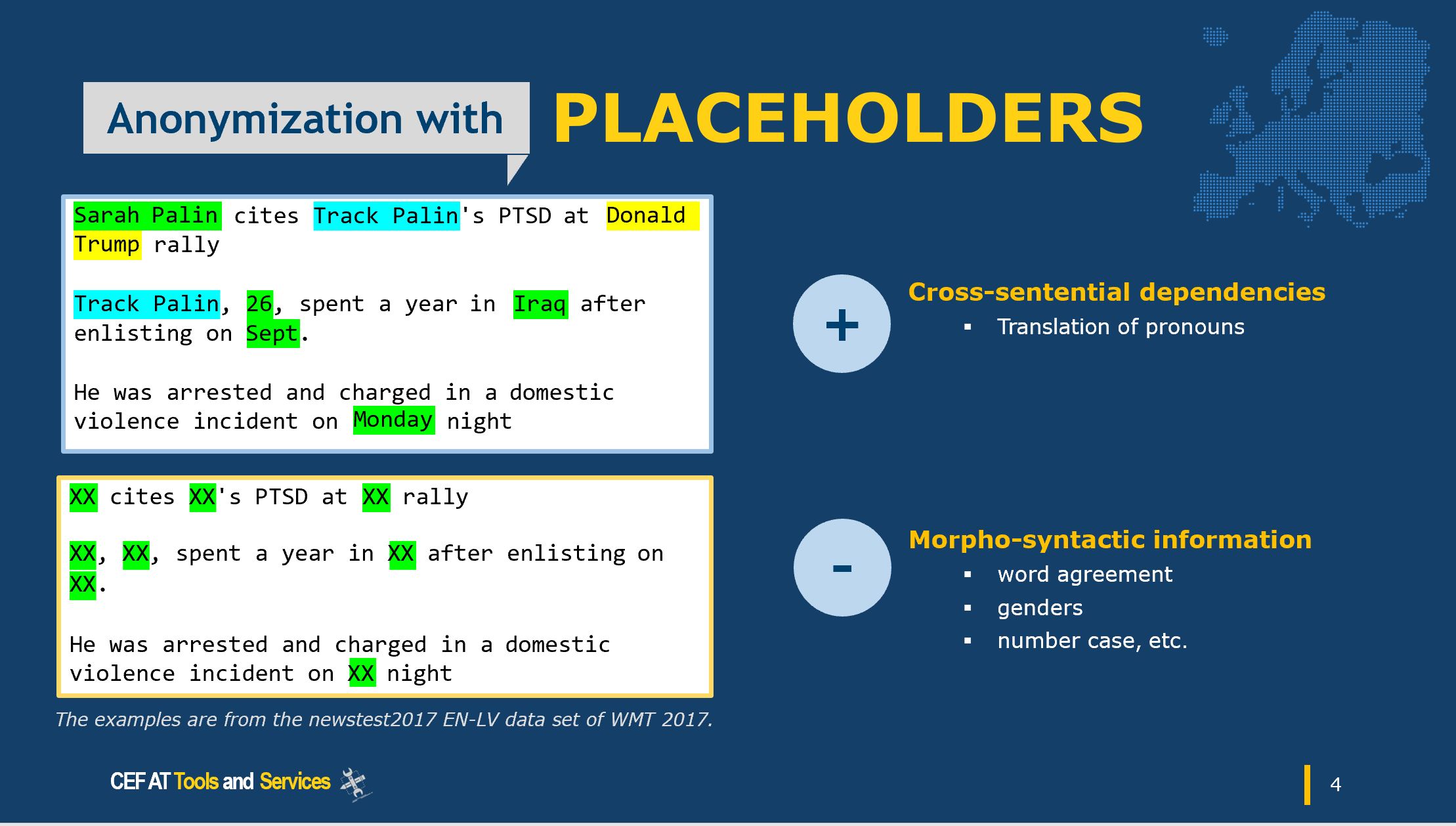

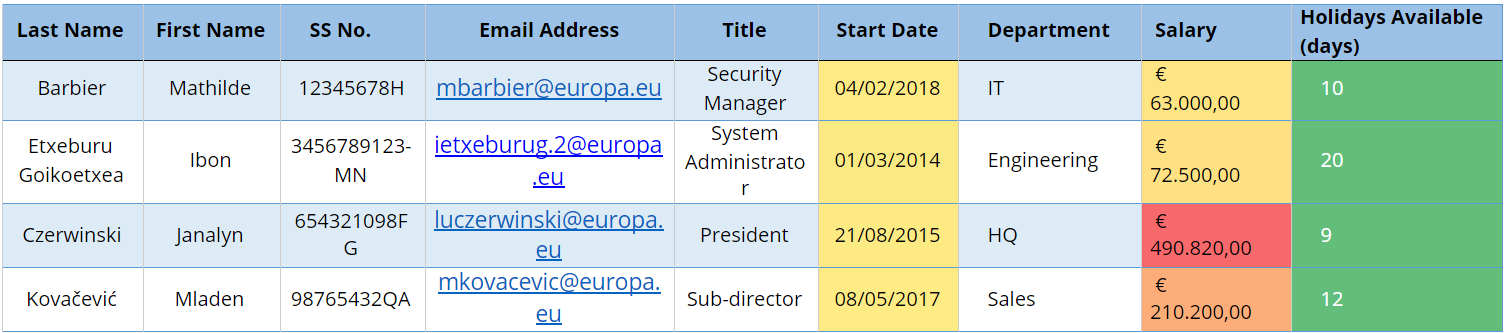 Fig 1 — Table before anonymisation
Fig 1 — Table before anonymisation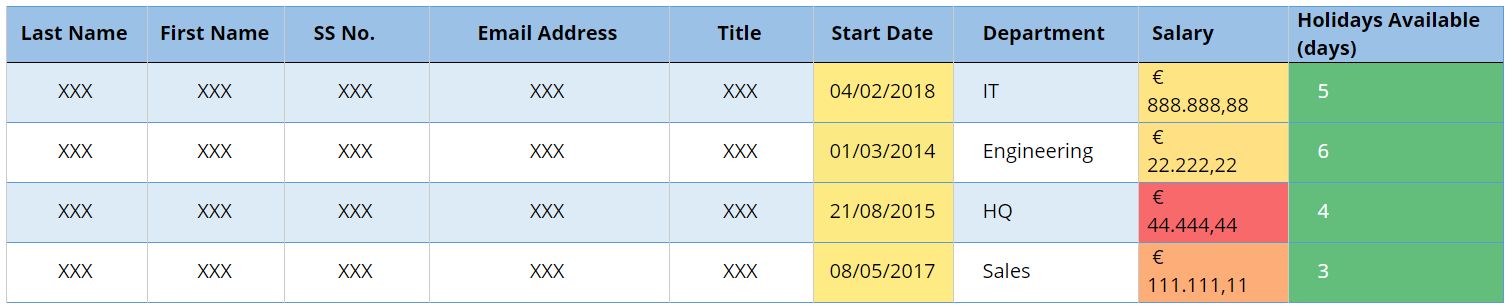 Fig 2 — Table after anonymisation
Fig 2 — Table after anonymisation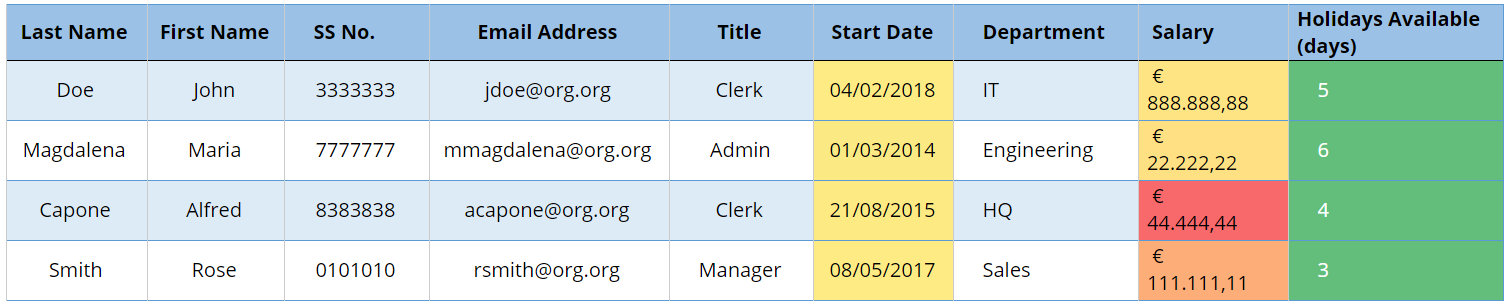 Fig 3 — Table after Pseudonymisation (Case A).
Fig 3 — Table after Pseudonymisation (Case A). Fig 3 — Table after Pseudonymisation (Case B)
Fig 3 — Table after Pseudonymisation (Case B)